The CDC 6500 has led a rough life over the last 6 months or so: way back on the afternoon of July 2, 2018, I got an email from the CDC’s Power Control PLC telling me that it had to turn off the computer because the cooling water was too hot! A technician came out and found that the chiller was low on refrigerant. He brought it back up to the proper level, and went away. Next morning it was down again.
After much gnashing of teeth and tearing of hair, it was determined that the compressor was bad in the chiller. “We’ll have a new one in 5 weeks!” The new one turned out to be bad too, and so another was ordered, that was easier to get. Only about 3 weeks, instead of the 8 that the official one took. That worked for a few weeks, and the CDC went down again because the water was too hot.
This time it was very puzzling because as long as the technician was here, it worked fine. He spent most of a morning watching it, decided it was OK, and left, but he didn’t make it to the freeway before it went down again. He came back, and watched for the rest of the afternoon, and found that the main condenser fan would overheat, and shut down, causing the backup fan to come on. The load wasn’t very high, so the backup fan had to cycle on and off, while the main fan motor cooled off. This would go on for a while, till both motors were off at the same time, and then the compressor would go over pressure because the condenser fans were off, and the chiller would stop cooling, resulting in the “Water too HOT” computer shutdown.
Another week went by waiting for replacement fan motors from the chiller manufacturer, with no luck. Eventually we gave up and got new fan motors locally, installed them and the chiller has been working since. While the CDC didn’t seem to mind being off for 102 days for the compressor problem, it didn’t like being off for 3 weeks while we fiddled with the fans.
Both when it was off for 102 days, and this time, we found that Bay 1 was low on refrigerant. The first time we just filled it up, but the second time we looked closer, and found that there is a small leak where the power wires go into the Bay 1 compressor. The compressor manufacturer, the same guys that made the chillers compressor, will gladly sell us a new compressor, but the parts for the 50 year old, R12 compressor, are no longer available. We are working on that, but I haven’t heard that we found the parts yet.
Back to more recent times: now that the chiller is chillin’, and the CDC’s cooling system is coolin’, why isn’t the computer computing?
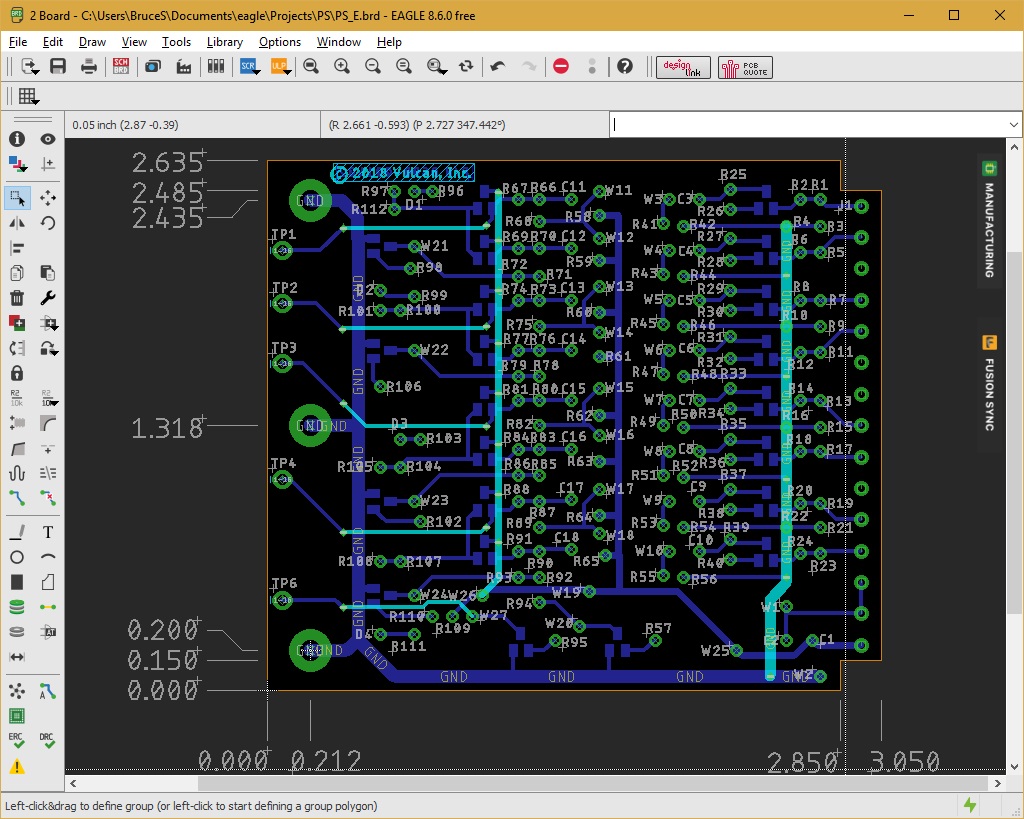
Let’s run some diagnostics and see what happens: I try to run my CDC diagnostic tape, but the machine complains that Central Memory doesn’t seem to be available. No, I didn’t run the real tape drives, I ran the imaginary one that uses a disk file on a PC to pretend to be a tape drive. Anyway, that didn’t work, so I flip the zillion or so Dead Start switches in my emulated Dead Start panel, to fire up my Central processor based memory test, and get no display at all! This is distinctly unusual. Let’s try my PP based Central Memory test: That seems to work till it finishes writing all of memory, then the display goes blank. Is there a pattern here?
I put a scope probe on the memory request line inside the memory controller in Chassis 3, and find that someone is requesting memory every possible cycle. There are four possible requests: the Peripheral Processors as a group get a request line, each Central Processor gets a request line, and the missing Extended Core Memory gets a request. Let’s find out who it is: the PP’s aren’t doing it, neither of the CP’s are doing it, and the non-existent ECM isn’t doing it. Huh? Nobody is wants it, but ALL of it is getting requested!
I am going to step back a little bit, and try to explain why it sometimes takes me a while to fix this beast. This machine was designed before there were any standards about logic diagrams. Every manufacturer had to come up with their own scheme for schematics. Here is one where I found a problem, but we will get to that in a bit.
Now when there are two squares with one above the other, and arrows from each going to the other, those are flip-flops. When you have a square, or a circle with multiple arrows going into it, that is a gate. Which one is an “or” gate, and which one is an “and” gate? Sorry, you have to figure out that for your self, because the CDC documentation says either one can be either one. The triangle with a number in it would be a test point on the edge of the module. The two overlapping circles, kind of like an elipsis, indicate that is a coax cable receiver, as opposed to a regular twisted pair signal. A “P” followed by a number indicates a pin of the module.
This module receives the PP read and write signals from the PP’s in chassis 1, on pins P19 and P24. On the right side of the diagram, you can see where all the pins connect. If we look at pin 24, we can see it connects to W07 wire 904, and pin 19 is connected to W07-903. The W “Jack”s are coax cables, the other letter signals go somewhere inside this chassis.
Really, what we are looking at here, is that a circle, or a square is the collector pull-up resistor of one or more silicon NPN transistors. the arrow heads are the base of the transistors, and the line coming into the head has a base resistor in it. If there are three arrows coming into a square, like at the bottom, those three 2n2369 transistors all have their collectors tied together, with one pull-up resistor. I could be slow, because it took about 6 months before I felt I was at all fluent in reading these logic diagrams.
Now we have to talk about the Central Memory Architecture a bit. The CDC has 32 banks of 16K words of memory. Each of these banks is separate, and they can be interleaved any way the 4 requestors ask for them. At the moment, I am only running half of them, because there is something wrong with the other half. Each of these banks does a complete cycle in 1uS. The memory controller in chassis 3 can put out an address every 100nS, along with whether it is for a read or a write. This request goes to all banks in parallel. If the bank that it points to is available, he will send back an “accept” pulse, and that requestor is free to ask for something else. If the controller doesn’t get an “accept” he will ask again in about 400nS. There is a bunch of modules involved in this dance, and it is a big circle.
A little more background: This machine was designed before there was such a thing as plated through holes on printed circuit boards. The two boards in each module were double sided. What they did when they needed to get to the other side of a PCB, was they would put a tiny brass rivet in the via hole, and solder both sides.
What I eventually found was that the signal from P23 of the module in 3L34, wasn’t making it to pin 15! There was a via rivet that wasn’t making its connection to the other side of the board. I re-soldered all the vias on that module, and now we were only requesting memory when someone wanted it!
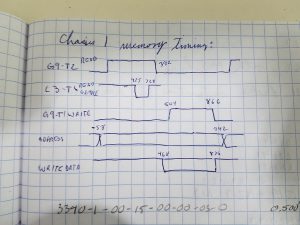
Now that we can request memory and have a reasonable chance of it responding correctly, it is on to testing memory. I loaded up my CP based test, and it ran… for a while. Then it quit, with a very strange error. The test uses a single bit, and its complement to check the existence of every location of memory. It will read a location, and compare it with what should be there, and put the difference in a second register. Normally I would expect a single bit error, or maybe 12 bits if a module failed that way. The result looked like 59 bad bits, or the error being exactly the same as what it read. Usually this is because the CPU that is running the test is miss-executing the compare instruction.
While I was thinking about that, I ran Exchange Jump Test to see what that said. A PP can cause a CP to swap all its registers, including the Program Counter with the contents of some memory that the PP points to. This is called an Exchange Jump. The whole process happens in about 2.6uS as it requests 16 banks of memory in a sequence. This works the memory pretty hard. Exchange Jump Test (EJT) would fail after a while, and as I looked at the results, I noticed that it was usually failing a certain bit in bank 7. I checked, and noticed it was an original memory module, so I looked at my bench and found I didn’t have any new ones assembled, so I had to put the sides on a couple of finished PCB assemblies, and test them. I then swapped out the old memory in bank 7 with a new semiconductor memory, and EJT passed!
I then checked to see if my CP based memory test worked, and it did too. We are back in Business after over 5 months. I am keeping my fingers crossed in the hope that the chiller stays alive for a while.
Bruce Sherry